Local Learning Abstraction: Trainer
FederatedScope decouples the local learning process and details of FL communication and schedule, allowing users to freely customize local learning algorithm via the trainer. Each worker holds a trainer object to manage the details of local learning, such as the loss function, optimizer, training step, evaluation, etc.
In this tutorial, you will learn:
- The structure of
Trainerused in FederatedScope; - How the
Trainermaintains attributes and how to extend new attributes? - How the
Trainermaintains learning behaviors and how to extend new behaviors? - How to extend
Trainerto learn with more than one internal model?
Trainer Structure
A typical machine learning process consists of the following procedures:
- Preparing datasets and pre-extracting data mini-batches
- Iterations over training datasets to update the model parameters
- Evaluation the quality of learned model on validation/evaluation datasets
- Saving, loading, and monitoring the model and intermediate results
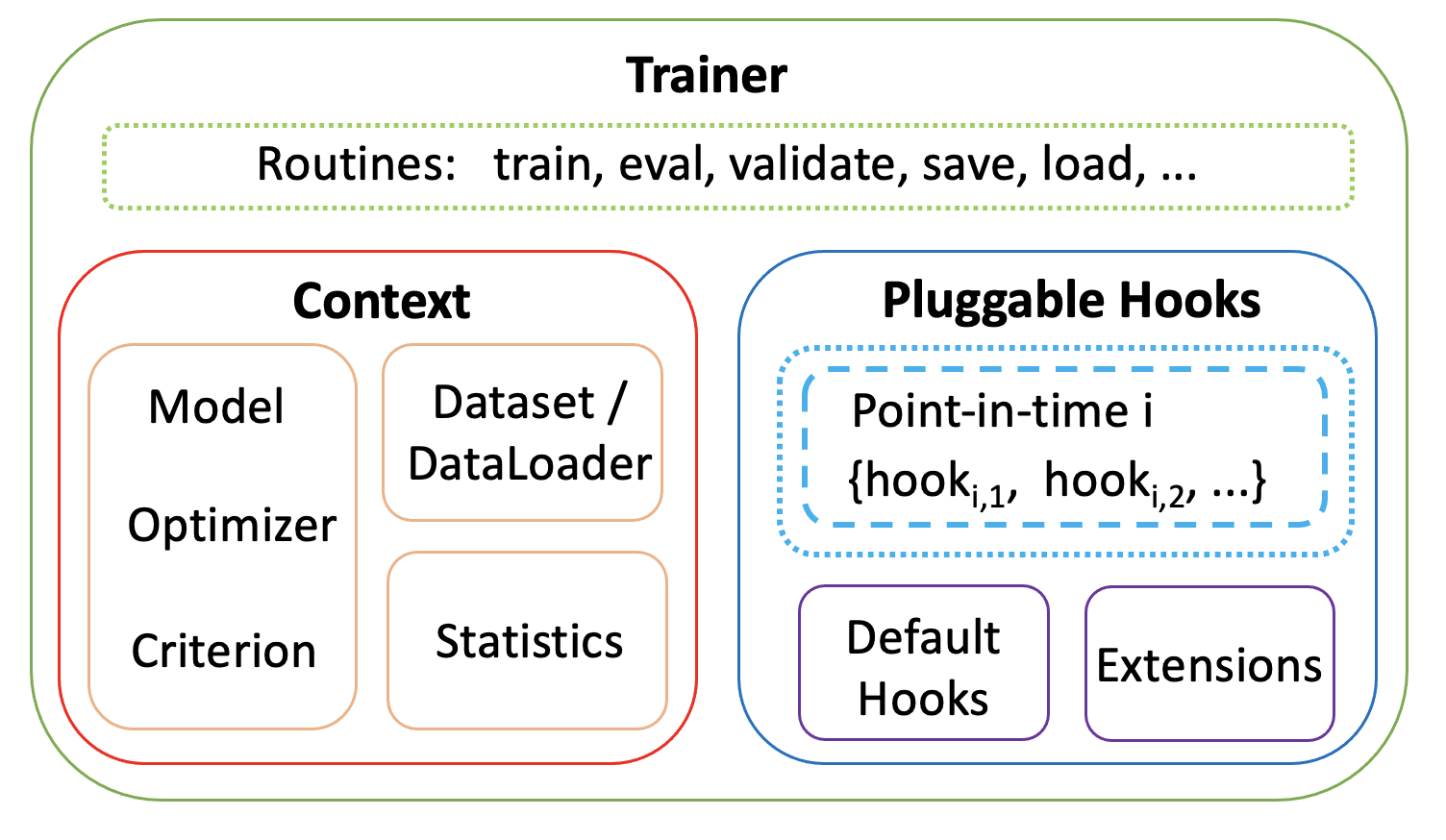
As the figure shows, in FederatedScope Trainer, these above procedures are provided with high-level routines abstraction, which are made up of Context class and several pluggable Hooks.
- The
Contextclass is used to holds learning-related attributes, including data, model, optimizer and etc. We will introduce more details in next Section.self.ctx = Context(model, self.cfg, data, device, init_dict=self.parse_data(data)) - The
Hooksrepresent fine-grained learning behaviors at different point-in-times, which provides a simple yet powerful way to customize learning behaviors with a few modifications and easy re-use of fruitful default hooks. More details about the behavior customization are in following Section. ```python HOOK_TRIGGER = [ “on_fit_start”, “on_epoch_start”, “on_batch_start”, “on_batch_forward”, “on_batch_backward”, “on_batch_end”, “on_epoch_end”, “on_fit_end” ] self.hooks_in_train = collections.defaultdict(list)By default, use the same trigger keys
self.hooks_in_eval = copy.deepcopy(self.hooks_in_train) self.hooks_in_ft = copy.deepcopy(self.hooks_in_train)
register necessary hooks into self.hooks_in_train and
self.hooks_in_eval
if not only_for_eval: self.register_default_hooks_train() if self.cfg.finetune.before_eval: self.register_default_hooks_ft() self.register_default_hooks_eval()
## Trainer Behaviors
### Routines
- Besides the common I/O procedures `save_model` and `load_model`, FederatedScope trainer uses the `update` function to load the model from FL clients.
- For the train/eval/validate procedures, FederatedScope implements them via calling a general `_run_routine` with different datasets, hooks_set and running mode.
def _run_routine(self, mode, hooks_set, dataset_name=None)
- We decouple the learning process with several fine-grained point-in-time and calling all registered hooks at specific point-in-times as follows
```python
@lifecycle(LIFECYCLE.ROUTINE)
def _run_routine(self, mode, hooks_set, dataset_name=None):
"""Run the hooks_set and maintain the mode
Arguments:
mode: running mode of client, chosen from train/val/test
Note:
Considering evaluation could be in ```hooks_set["on_epoch_end"]```, there could be two data loaders in
self.ctx, we must tell the running hooks which data_loader to call and which num_samples to count
"""
for hook in hooks_set["on_fit_start"]:
hook(self.ctx)
self._run_epoch(hooks_set)
for hook in hooks_set["on_fit_end"]:
hook(self.ctx)
return self.ctx.num_samples
@lifecycle(LIFECYCLE.EPOCH)
def _run_epoch(self, hooks_set):
for epoch_i in range(self.ctx.get(f"num_{self.ctx.cur_split}_epoch")):
self.ctx.cur_epoch_i = CtxVar(epoch_i, "epoch")
for hook in hooks_set["on_epoch_start"]:
hook(self.ctx)
self._run_batch(hooks_set)
for hook in hooks_set["on_epoch_end"]:
hook(self.ctx)
@lifecycle(LIFECYCLE.BATCH)
def _run_batch(self, hooks_set):
for batch_i in range(self.ctx.get(f"num_{self.ctx.cur_split}_batch")):
self.ctx.cur_batch_i = CtxVar(batch_i, LIFECYCLE.BATCH)
for hook in hooks_set["on_batch_start"]:
hook(self.ctx)
for hook in hooks_set["on_batch_forward"]:
hook(self.ctx)
for hook in hooks_set["on_batch_backward"]:
hook(self.ctx)
for hook in hooks_set["on_batch_end"]:
hook(self.ctx)
# Break in the final epoch
if self.ctx.cur_mode in [MODE.TRAIN, MODE.FINETUNE] and self.ctx.cur_epoch_i == self.ctx.num_train_epoch - 1:
if batch_i >= self.ctx.num_train_batch_last_epoch - 1:
break
```
### Hooks
- We implement fruitful default hooks to support various training/evaluation processes, such as [personalized FL behaviors](/docs/pfl/#demonstration), [graph-task related behaviors](/docs/graph/#develop-federated-gnn-algorithms), [privacy-preserving behaviors](/docs/privacy-attacks/#2-usage-of-attack-module).
- Each hook takes the learning `context` as input and performs the learning actions such as
- prepare model and statistics
```python
def _hook_on_fit_start_init(ctx):
# prepare model and optimizer
ctx.model.to(ctx.device)
if ctx.cur_mode in [MODE.TRAIN, MODE.FINETUNE]:
# Initialize optimizer here to avoid the reuse of optimizers
# across different routines
ctx.optimizer = get_optimizer(ctx.model,
**ctx.cfg[ctx.cur_mode].optimizer)
ctx.scheduler = get_scheduler(ctx.optimizer,
**ctx.cfg[ctx.cur_mode].scheduler)
# prepare statistics
ctx.loss_batch_total = CtxVar(0., LIFECYCLE.ROUTINE)
ctx.loss_regular_total = CtxVar(0., LIFECYCLE.ROUTINE)
ctx.num_samples = CtxVar(0, LIFECYCLE.ROUTINE)
ctx.ys_true = CtxVar([], LIFECYCLE.ROUTINE)
ctx.ys_prob = CtxVar([], LIFECYCLE.ROUTINE)
```
- calculate loss in forward stage
```python
def _hook_on_batch_forward(ctx):
x, label = [_.to(ctx.device) for _ in ctx.data_batch]
pred = ctx.model(x)
if len(label.size()) == 0:
label = label.unsqueeze(0)
ctx.y_true = CtxVar(label, LIFECYCLE.BATCH)
ctx.y_prob = CtxVar(pred, LIFECYCLE.BATCH)
ctx.loss_batch = CtxVar(ctx.criterion(pred, label), LIFECYCLE.BATCH)
ctx.batch_size = CtxVar(len(label), LIFECYCLE.BATCH)
```
- update model parameters in backward stage
```python
def _hook_on_batch_backward(ctx):
ctx.optimizer.zero_grad()
ctx.loss_task.backward()
if ctx.grad_clip > 0:
torch.nn.utils.clip_grad_norm_(ctx.model.parameters(),
ctx.grad_clip)
ctx.optimizer.step()
if ctx.scheduler is not None:
ctx.scheduler.step()
```
- To customize more trainer behaviors, users can reset and replace existing hooks, or register new hooks
- Users can freely check the current hook set via print `trainer.hooks_in_train` and `trainer.hooks_in_eval`.
- For delete case, users can either 1) reset all the hooks at a target point-in-time trigger; or 2) a specific hook by passing the target function name `hook_name ` in train/eval hook set.
```python
def reset_hook_in_train(self, target_trigger, target_hook_name=None)
def reset_hook_in_eval(self, target_trigger, target_hook_name=None)
- For create case, we allows registering a new hook at a target point-in-time trigger, and support 1) specifying a specific positions (i.e., the order a hook called within the trigger set); or 2) inserting before or after a base hook
```python
def register_hook_in_train(self,
new_hook,
trigger,
insert_pos=None,
base_hook=None,
insert_mode="before")
-
For update case, we provide functions to replace existing hook (by name) with a new_hook (function)
def replace_hook_in_train(self, new_hook, target_trigger, target_hook_name)
Customized Data Preparation
- We provide the data pre-processing operations in
parse_datafunction, which parses the dataset and initializes the variables{}_data,{}_loader, and the counternum_{MODE}_dataaccording to the types of datasets withindataas follows.
def parse_data(self, data):
"""Populate "{}_data", "{}_loader" and "num_{}_data" for different modes
"""
# TODO: more robust for different data
init_dict = dict()
if isinstance(data, dict):
for mode in ["train", "val", "test"]:
init_dict["{}_data".format(mode)] = None
init_dict["{}_loader".format(mode)] = None
init_dict["num_{}_data".format(mode)] = 0
if data.get(mode, None) is not None:
if isinstance(data.get(mode), Dataset):
init_dict["{}_data".format(mode)] = data.get(mode)
init_dict["num_{}_data".format(mode)] = len(
data.get(mode))
elif isinstance(data.get(mode), DataLoader):
init_dict["{}_loader".format(mode)] = data.get(mode)
init_dict["num_{}_data".format(mode)] = len(
data.get(mode).dataset)
elif isinstance(data.get(mode), dict):
init_dict["{}_data".format(mode)] = data.get(mode)
init_dict["num_{}_data".format(mode)] = len(
data.get(mode)['y'])
else:
raise TypeError("Type {} is not supported.".format(
type(data.get(mode))))
else:
raise TypeError("Type of data should be dict.")
return init_dict
- To support customized dataset, please implement the function
parse_datain the new trainer and initialize the following variables.{train/test/val}_data: the data object,{train/test/val}_loader: the data loader object,num_{train/test/val}_data: the number of samples within the dataset.
Trainer Context
Context class is an implementation of messager within the trainer. All variables within it can be called by ctx.{VARIABLE_NAME}.
As stated above, both the training and evaluation processes are consisted of independent hook functions, which only receive an instance of Context as the sole parameter. Therefore, the parameter ctx should
- maintain the references of objects (e.g. model, data, optimizer),
- provide running parameters (e.g. number of training epochs),
- indicate the current operating status (e.g. train/test/validate) and the current selected data split (e.g. the train/test/validate split), and
- maintain and manage statistical variables (e.g. loss, output, accuracy).
Maintain the References of Objects
During federated training and evaluation, Context needs to maintain some necessary objects, such as
model: The FL training/evaluation model,data: The dataset used in FL training/evaluation,device: The specific device, andcriterion: The specific loss function.
Note the above references of objects are all shared across different routines.
Provide running parameters
Some parameters are calculated within the routine, such as
- the number of training/test/validate epochs,
- the total number of training/test/valiate batches,
- the number of the batches within the last training epoch,
For now, the above running parameters are calculated by the setup_vars function in Context.
def setup_vars(self):
if self.cfg.backend == 'torch':
self.trainable_para_names = get_trainable_para_names(self.model)
self.criterion = get_criterion(self.cfg.criterion.type,
self.device)
self.regularizer = get_regularizer(self.cfg.regularizer.type)
self.grad_clip = self.cfg.grad.grad_clip
elif self.cfg.backend == 'tensorflow':
self.trainable_para_names = self.model.trainable_variables()
self.criterion = None
self.regularizer = None
self.optimizer = None
self.grad_clip = None
# Process training data
if self.get('train_data', None) is not None or self.get(
'train_loader', None) is not None:
# Calculate the number of update steps during training given the
# local_update_steps
self.num_train_batch, self.num_train_batch_last_epoch, self.num_train_epoch, self.num_total_train_batch = calculate_batch_epoch_num(
self.cfg.train.local_update_steps,
self.cfg.train.batch_or_epoch, self.num_train_data,
self.cfg.data.batch_size, self.cfg.data.drop_last)
# Process evaluation data
for mode in ["val", "test"]:
setattr(self, "num_{}_epoch".format(mode), 1)
if self.get("{}_data".format(mode)) is not None or self.get(
"{}_loader".format(mode)) is not None:
setattr(
self, "num_{}_batch".format(mode),
getattr(self, "num_{}_data".format(mode)) //
self.cfg.data.batch_size +
int(not self.cfg.data.drop_last and bool(
getattr(self, "num_{}_data".format(mode)) %
self.cfg.data.batch_size)))
Indicate the Current Operating Status and the Selected Dataset
The Context class uses two attributes to indicate the current operating status (cur_mode) and selected dataset (cur_split).
cur_mode
The value of cur_mode is selected among MODE.TRAIN, MODE.FINETUNE, MODE.TEST and MODE.VAL as follows.
You can find the enum class in federatedscope/core/auxiliaries/enums.py.
class MODE:
"""
Note:
Currently StrEnum cannot be imported with the environment
`sys.version_info < (3, 11)`, so we simply create a MODE class here.
"""
TRAIN = 'train'
TEST = 'test'
VAL = 'val'
FINETUNE = 'finetune'
At the beginning of one routine, we will check cur_mode to
- change the status of the models
- execute
model.train()ifcur_modeequalsMODE.TRAINorMODE.FINETUNE, and - execute
model.eval()ifcur_modeequalsMODE.TESTorMODE.VAL
- execute
cur_split
The attribute cur_split indicates which part of dataset that the routine will use, and the printed metrics will be named with a cur_split prefix.
In general setting, the dataset is divided into train, test and validate splits.
class MetricCalculator(object):
...
def eval(self, ctx):
results = {}
y_true, y_pred, y_prob = self._check_and_parse(ctx)
for metric, func in self.eval_metric.items():
results["{}_{}".format(ctx.cur_split,
metric)] = func(ctx=ctx,
y_true=y_true,
y_pred=y_pred,
y_prob=y_prob,
metric=metric)
By default, the training routine will execute on the train split, and the evaluation routine will execute on the test and validate splits.
However, you can also specify the split by the argument target_data_split_name.
def train(self, target_data_split_name="train", hooks_set=None):
...
def evaluate(self, target_data_split_name="test", hooks_set=None):
...
def finetune(self, target_data_split_name="train", hooks_set=None):
...
Maintain and Manage Statistical Variables
The statistical variables include average/total training/test loss, number of training/test samples and so on.
Theoretically, the lifecycle of all the statistical variables should be within the routine.
FederatedScope achieves automatic lifecycle management by a wrapper class CtxVar and a decorator @lifecycle.
The class CtxVar takes two arguments, where obj is the value of the statistical variable, and lifecycle is chosen from the enum class federatedscope.core.auxiliaries.enums.LIFECYCLE.
class CtxVar(object):
"""Basic variable class
Arguments:
lifecycle: specific lifecycle of the attribute
"""
LIEFTCYCLES = ["batch", "epoch", "routine", None]
def __init__(self, obj, lifecycle=None):
assert lifecycle in CtxVar.LIEFTCYCLES
self.obj = obj
self.lifecycle = lifecycle
Taking the average loss as an example, you can initialize a statistical variable loss_total as follows,
def _hook_on_fit_start(ctx):
ctx.loss_total = CtxVar(0., LIFECYCLE.ROUTINE)
LIFECYCLE.ROUTINE indicates the variable loss_total will be deleted automatically at the end of the routine.
Note
- The wrapper class
CtxVaris only used to record the lifecycle and won’t influence the usage of the variable. e.g. in the above exampletype(ctx.loss_total)still equalsfloat.
While the decorator @lifecycle(lifecycle) decides which variables will be deleted after running the decorated function.
In the following example the variables created with CtxVar(xxx, LIFECYCLE.EPOCH) will be deleted after executing _run_epoch.
@lifecycle(LIFECYCLE.EPOCH)
def _run_epoch(self, hooks_set):
for epoch_i in range(self.ctx.get(f"num_{self.ctx.cur_split}_epoch")):
self.ctx.cur_epoch_i = CtxVar(epoch_i, "epoch")
for hook in hooks_set["on_epoch_start"]:
hook(self.ctx)
self._run_batch(hooks_set)
for hook in hooks_set["on_epoch_end"]:
hook(self.ctx)
NOTE
- The users can also manage the variables all by themselves. However, you must check the lifecycle of the record varibales carefully, and release them once they are not used. An unreleased variable may cause memory leakage during federated learning. Feel free to implement your own algorithm in FederatedScope!
Multi-model Trainer
Several learning methods may leverage multiple models in each client such as clustering based method [1] and multi-task learning based method [2], FederatedScope implements the MultiModelTrainer class to meet this requirement.
-
We instantiate multiple models, optimizer objects & hook_sets as lists for
MultiModelTrainer. Different internal models can have different hook_sets and optimizers to support diverse multi-model based methodsself.init_multiple_models() # -> self.ctx.models = [...] # -> self.ctx.optimizers = [...] self.init_multiple_model_hooks() # -> self.hooks_in_train_multiple_models = [...] # -> self.hooks_in_eval_multiple_models = [...] -
To enable easy extension, we support copy initialization from a single-model trainer.
# By default, the internal models & optimizers are the same type additional_models = [ copy.deepcopy(self.ctx.model) for _ in range(self.model_nums - 1) ] self.ctx.models = [self.ctx.model] + additional_models -
We can customized hooks and optimizers for multi-model interaction. Specifically, two types of internal model interaction mode are built in
MultiModelTrainer.-
# assert models_interact_mode in ["sequential", "parallel"] self.models_interact_mode = models_interact_mode -
The
sequentialinteraction mode indicates the interaction are conducted at run_routine level[one model runs its whole routine, then do sth. for interaction, then next model runs its whole routine] ... -> run_routine_model_i -> _switch_model_ctx -> (on_fit_end, _interact_to_other_models) -> run_routine_model_i+1 -> ... -
The
parallelinteraction mode indicates the interaction are conducted at point-in-time level[At a specific point-in-time, one model call hooks (including interaction), then next model call hooks] ... -> (on_xxx_point, hook_xxx_model_i) -> (on_xxx_point, _interact_to_other_models) -> (on_xxx_point, _switch_model_ctx) -> (on_xxx_point, hook_xxx_model_i+1) -> ... -
Note that these two modes call
_switch_model_ctxat different positions. By default, we will switch cur_model, and optimizer, and users can override this function to support customized switch logicdef _switch_model_ctx(self, next_model_idx=None): if next_model_idx is None: next_model_idx = (self.ctx.cur_model_idx + 1) % len( self.ctx.models) self.ctx.cur_model_idx = next_model_idx self.ctx.model = self.ctx.models[next_model_idx] self.ctx.optimizer = self.ctx.optimizers[next_model_idx]
-
Reference
[1] Felix Sattler, Klaus-Robert Müller, and Wojciech Samek. “Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints”. In: IEEE Transactions on Neural Networks and Learning Systems (2020).
[2] Marfoq, Othmane, et al. “Federated multi-task learning under a mixture of distributions.” Advances in Neural Information Processing Systems 34 (2021).