Cross-Device FL
Background
A typical FL scenario is cross-device FL, which is pioneered by Google [1], and several efforts have been devoted to consumer applications such as mobile keyboard assistants [1,2,3,4] and audio keyword spotting [5,6,7].
The cross-device FL setting usually contains the following charateristics:
- massively parallel processing: there can be 10^4 ~ 10^10 mobile or IoT devices in an FL course;
- un-balanced and diverse local data: clients (devices) usually have heterogeneous data in terms of data quantity and data distributions;
- limited client-end resources: the client devices usually have limited hardware and communication resources that are much weaker than cloud servers. Low latency and low costs in storage, computation, and communication are much-needed in cross-device FL applications.
As the following figure shows, a typical cross-device FL process adopts a centralized network topology and involves the following repeated steps: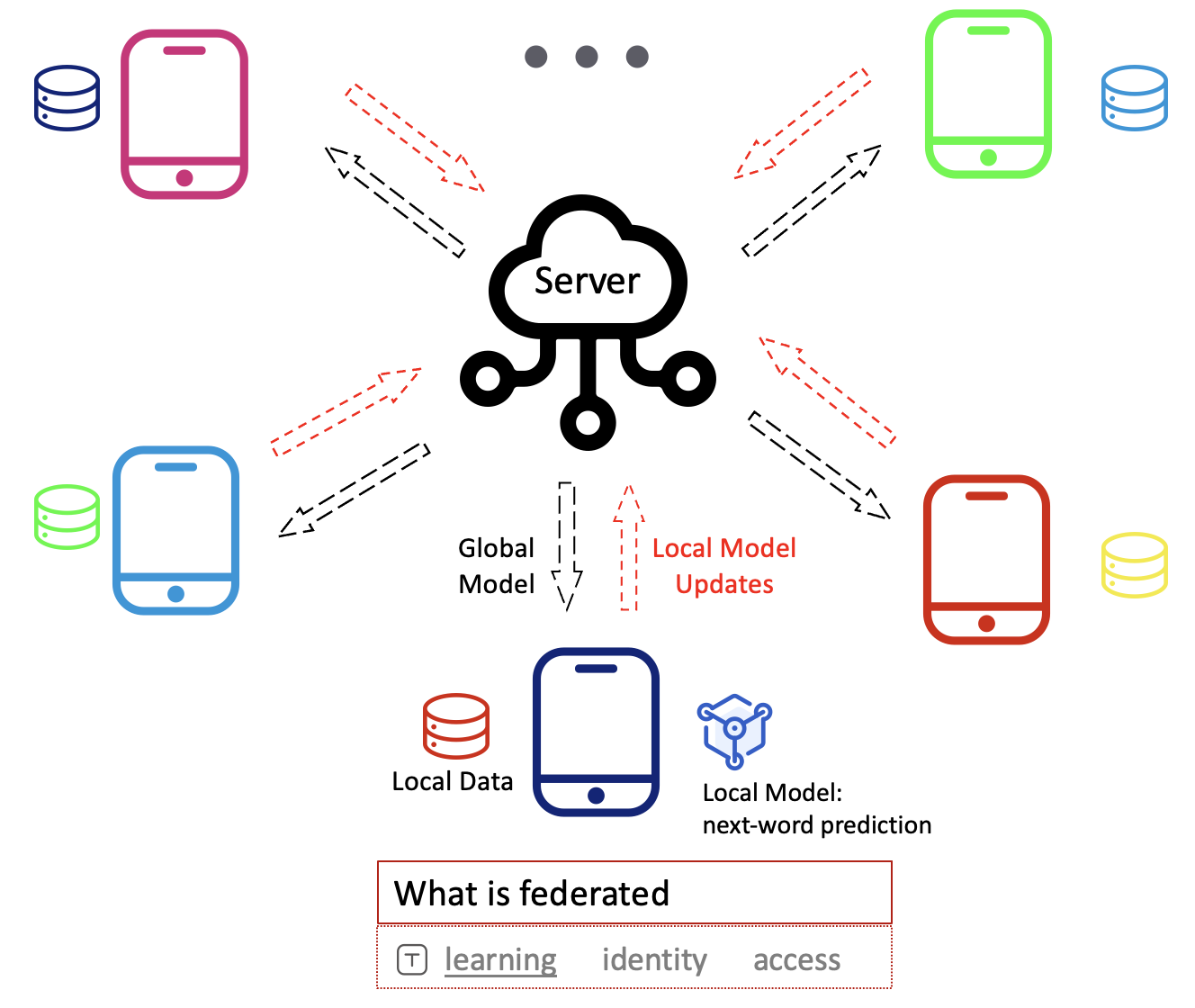
- Server broadcasts the intermediate exchange information (usually the global model weights) and (optional) the clients-end FL program to selected clients.
- The selected clients download the information from the server, and execute local learning based on the private local data, the FL programs, and the messages from the server.
- The selected clients upload the local update information such as model gradients to the server.
- The server collects and aggregates the update information from clients, and applies the updates into the intermediate exchange information (the shared global) for next-round federation.
Next we show how to run a cross-device FL simulation for next-character/word prediction task with our framework.
Example: LSTM on Shakespeare dataset
Next-character/word prediction is a classic NLP task as it can be applied in many consumer applications and appropriately be modeled by statistical language models, we show how to achieve the cross-device FL simulation for this task.
- Here we implement a simple LSTM model for next-character prediction: taking an English-character sequence as input, the model learns to predict the next possible character. After registering the modela we can use it by specifying
cfg.model.type=lstmand hyper-parameters such ascfg.model.in_channels=80, cfg.model.out_channels=80, cfg.model.emd_size=8. Complete codes are infederatedscope/nlp/model/rnn.pyandfederatedscope/nlp/model/model_builder.py.
class LSTM(nn.Module):
def __init__(self,
in_channels,
hidden,
out_channels,
n_layers=2,
embed_size=8):
super(LSTM, self).__init__()
self.in_channels = in_channels
self.hidden = hidden
self.embed_size = embed_size
self.out_channels = out_channels
self.n_layers = n_layers
self.encoder = nn.Embedding(in_channels, embed_size)
self.rnn =\
nn.LSTM(
input_size=embed_size,
hidden_size=hidden,
num_layers=n_layers,
batch_first=True
)
self.decoder = nn.Linear(hidden, out_channels)
def forward(self, input_):
encoded = self.encoder(input_)
output, _ = self.rnn(encoded)
output = self.decoder(output)
output = output.permute(0, 2, 1) # change dimension to (B, C, T)
final_word = output[:, :, -1]
return final_word
- For the dataset, we use the Shakespeare dataset from LEAF, which is built from The Complete Works of William Shakespeare, and partitioned to ~1100 clients (speaking roles) from 422615. We can specify the
cfg.dataset.type=shakespeareand adjust the fraction of data subsample (cfg.data.sub_sample=0.2), and train/val/test ratio (cfg.data.splits=[0.6,0.2,0.2). Complete NLP data codes are infederatedscope/nlp/dataset.
class LEAF_NLP(LEAF):
"""
LEAF NLP dataset from
leaf.cmu.edu
self:
root (str): root path.
name (str): name of dataset, ‘shakespeare’ or ‘xxx’.
s_frac (float): fraction of the dataset to be used; default=0.3.
tr_frac (float): train set proportion for each task; default=0.8.
val_frac (float): valid set proportion for each task; default=0.0.
"""
def __init__(
self,
root,
name,
s_frac=0.3,
tr_frac=0.8,
val_frac=0.0,
seed=123,
transform=None,
target_transform=None):
- To enable large-scale clients simulation, we provide online aggregator in standalone mode to save the memory, which maintains only three model objects for the FL server aggregation. We can use this feature by specifying
cfg.federate.online_aggr = Trueandfederate.share_local_model=True, more details about this feature can be found in the post “Simulation and Deployment”. - To handle the non-i.i.d. challenge, FederatedScope supports several SOTA personalization algorithms and easy extension.
- To enable partial clients participation in each FL round, we provide clients sampling feature with various configuration manners: 1)
cfg.federate.sample_client_rate, which is in the range (0, 1] and indicates selecting partial clients using random sampling with replacement; 2)cfg.federate.sample_client_num, which is an integer to indicate sample client number at each round. - With these specification, we can run the experiment with
python main.py --cfg federatedscope/nlp/baseline/fedavg_lstm_on_shakespeare.yaml. Other NLP related scripts to run the next-character prediction experiments can be found infederatedscope/nlp/baseline.
References
[1] McMahan, Brendan, et al. “Communication-efficient learning of deep networks from decentralized data.” AISTATS 2017.
[2] McMahan, H. Brendan, et al. “Learning differentially private recurrent language models.” ICLR 2018.
[3] Hard, Andrew, et al. “Federated learning for mobile keyboard prediction.” arXiv 2018.
[4] Chen, Mingqing, et al. “Federated learning of n-gram language models.” ACL 2019.
[5] Dimitriadis, Dimitrios, et al. “A federated approach in training acoustic models.” INTERSPEECH 2020.
[6] Cui, Xiaodong, Songtao Lu, and Brian Kingsbury. “Federated Acoustic Modeling for Automatic Speech Recognition.” ICASSP 2021.
[7] Apple. Designing for privacy (video and slide deck). Apple WWDC, https://developer.apple.com/ videos/play/wwdc2019/708, 2019.