LLM
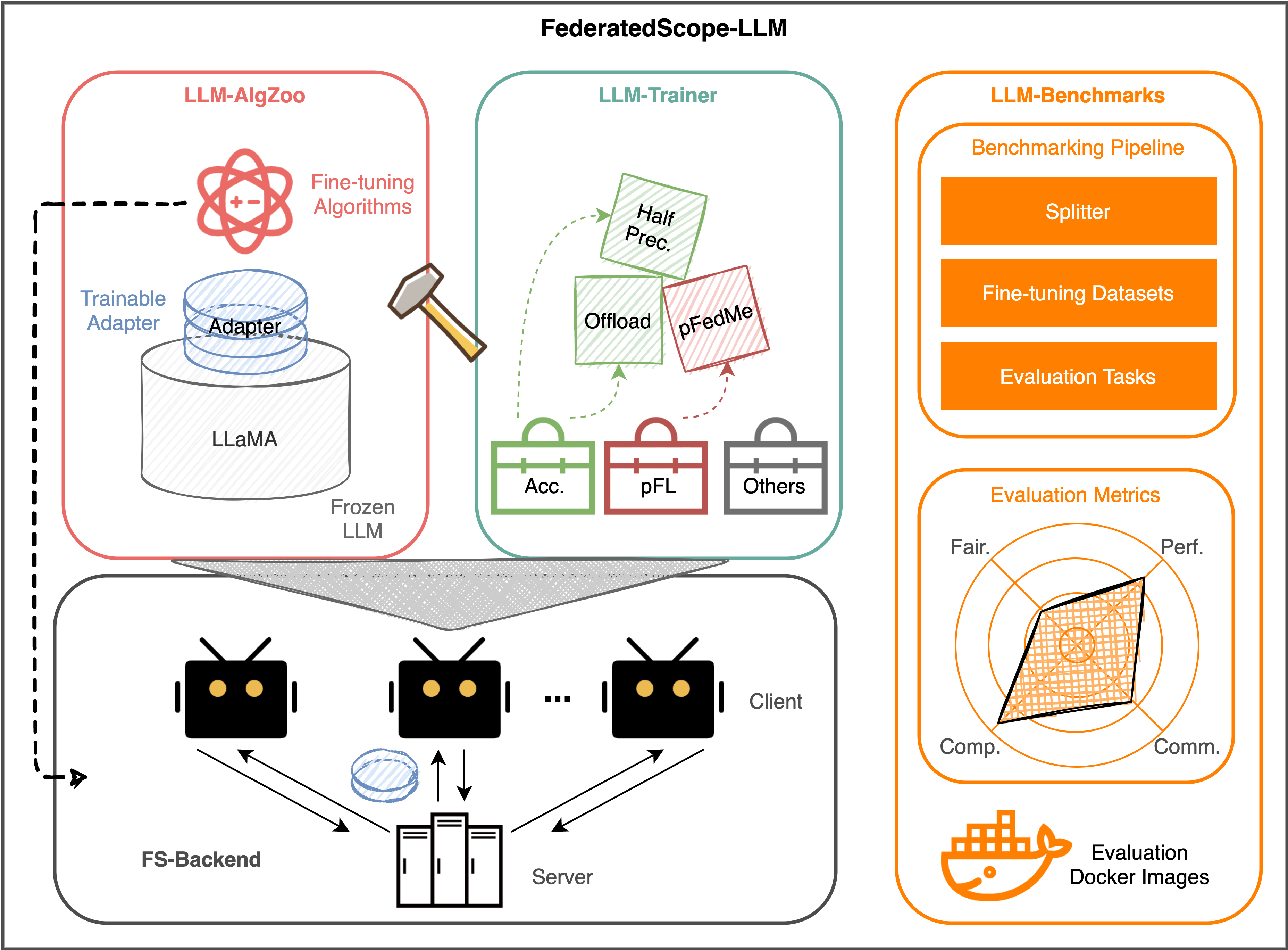
Introduction
FederatedScope-LLM (FS-LLM) is a comprehensive package for federated fine-tuning large language models, which provide:
- A complete end-to-end benchmarking pipeline, automizing the processes of dataset preprocessing, federated fine-tuning execution or simulation, and performance evaluation on federated LLM fine-tuning with different capability demonstration purposes;
- Comprehensive and off-the-shelf federated fine-tuning algorithm implementations and versatile programming interfaces for future extension to enhance the capabilities of LLMs in FL scenarios with low communication and computation costs, even without accessing the full model (e.g., closed-source LLMs);
- Several accelerating operators and resource-efficient operators for fine-tuning LLMs with limited resources and the flexible pluggable sub-routines for interdisciplinary study (e.g., LLMs in personalized FL).
For more details, please refer to our paper: FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning.
To facilitate further research and adoption, we release FS-LLM at this https URL.
In the tutorial, you will learn:
- The structure of FS-LLM [click]
- How to start fine-tuning LLMs with FederatedScope [click]
- How to use build-in functions [click]
- How to use built-in or create new fine-tuning datasets [click]
- How to use built-in evaluation tools [click]
- How to adopt different federated fine-tuning PEFT algorithms [click]
- How to enable different resource-efficiency operations [click]
- FAQ [click]
- Citation [click]
Code Structure
FederatedScope
├── federatedscope
│ ├── core # Federated learning backend modules
│ ├── llm # Federated fine-tuning LLMs modules
│ │ ├── baseline # Scripts for LLMs
│ │ ├── dataloader # Federated fine-tuning dataloader
│ │ ├── dataset # Federated fine-tuning dataset
│ │ ├── eval # Evaluation for fine-tuned LLMs
│ │ ├── misc # Miscellaneous
│ │ ├── model # LLMs and Adapter
│ │ ├── trainer # Fine-tuning with accerating operators
│ │ ├── ...
│ ├── main.py # Running interface
│ ├── ... ...
├── tests # Unittest modules for continuous integration
├── LICENSE
└── setup.py
Quick Start
Let’s start with fine-tuning GPT-2 on Alpaca to familiarize you with FS-LLM.
Step 1. Installation
The installation of FS-LLM is similar to minimal FS (see here for details), except that it requires Pytorch>=1.13.0 (we recommend version 2.0.X) because of the PEFT dependency:
# Create virtual environments with conda
conda create -n fs-llm python=3.9
conda activate fs-llm
# Install Pytorch>=1.13.0 (e.g., Pytorch==2.0.0)
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
# Install FS-LLM with editable mode
pip install -e .[llm]
Now, you have successfully installed the FS-LLM.
Step 2. Run with exmaple config
Before running, you should change your git branch to llm.
Now, you can fine-tune a GPT2 on Alpaca with FedAvg.
python federatedscope/main.py --cfg federatedscope/llm/baseline/testcase.yaml
Start with Built-in Functions
You can easily run through a customized yaml file. Here we only introduce the configuration related to FS-LLM, other configurations please refer to Configurations. For more examples, please refer to federatedscope/llm/baseline.
# For this configuration, you might need a GPU with at least 32GB of video memory to run.
# Whether to use GPU
use_gpu: True
# Deciding which GPU to use
device: 0
# Early stop steps, set `0` to disable
early_stop:
patience: 0
# Federate learning related options
federate:
# `standalone` or `distributed`
mode: standalone
# Number of communication round
total_round_num: 500
# Saving path for ckpt
save_to: "llama_rosetta_9_fed.ckpt"
# Number of dataset being split
client_num: 9
# Enable for saving memory, all workers share the same model instance
share_local_model: True
# Dataset related options
data:
# Root directory where the data stored
root: data/
# Dataset name
type: 'rosetta_alpaca@llm'
# Train/val/test splits
splits: [0.89,0.1,0.01]
# Use meta inforamtion to split `rosetta_alpaca`
splitter: 'meta'
# LLM related options
llm:
# Max token length for model input (training)
tok_len: 650
# ChatBot related options
chat:
# Max token length for model input (inference)
max_len: 1000
# Max number of history texts
max_history_len: 10
# Path for store model cache, default in `~/.cache/`
cache:
model: ''
# PEFT related options
adapter:
# Set ture to enable PEFT fine-tuning
use: True
# Args for PEFT fine-tuning
args: [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ]
# DataLoader related options
dataloader:
# Batch size for iter loader
batch_size: 1
# Model related options
model:
# Model type (format: {MODEL_REPO}@huggingface_llm)
type: 'decapoda-research/llama-7b-hf@huggingface_llm'
# Train related options
train:
# Number of local update steps
local_update_steps: 30
# `batch` or `epoch` for local_update_steps
batch_or_epoch: batch
# Optimizer related options
optimizer:
# Learning rate
lr: 0.003
# Weight decay
weight_decay: 0.0
# Set ture to enable `model.half()`
is_enable_half: True
# Trainer related options
trainer:
# Trainer type
type: llmtrainer
# Evaluation related options
eval:
# Frequency of evaluation
freq: 50
# Evaluation metrics
metrics: ['loss']
# Set key to track best model
best_res_update_round_wise_key: val_loss
Fine-tuning Dataset
In general, we use instruction SFT following Alpaca team. And in standalone mode, all dataset can be split into several clients with spesific splitter (i.e., lda, meta, iid) and federate.num_client.
Built-in Data
| data.type | Source | Note |
|---|---|---|
alpaca@llm |
Link | IIDSplitter |
alpaca_cleaned@llm |
Link | IIDSplitter |
dolly-15k@llm |
Link | LDASplitter or MetaSplitter split to 8 clients. |
gsm8k@llm |
Link | IIDSplitter |
rosetta_alpaca@llm |
Link | LDASplitter or MetaSplitter split to 9 clients. |
code_search_net@llm |
Link | LDASplitter or MetaSplitter split to 6 clients. |
Self-maintained Data
FS-LLM also supports using your own dataset in the following format.
| data.type | Note |
|---|---|
YOU_DATA_NAME.json@llm |
Format: [{'instruction': ..., 'input': ..., 'output':...}], default key: instruction, input, output, category |
YOU_DATA_NAME.jsonl@llm |
Format of each line: {'instruction': ..., 'input': ..., 'output':...}, default key: instruction, input, output, category |
Evaluation Tools
You can evaluate model domain capability of fine-tuned models with easy-to-use evaluation tools.
FederatedScope
├── federatedscope
│ ├── llm
│ │ ├── eval
│ │ │ ├── eval_for_code
│ │ │ ├── eval_for_gsm8k
│ │ │ ├── eval_for_helm
│ │ │ ├── eval_for_mmlu
...
How to use:
For example, to evaluate the model fine-tuned with python federatedscope/main.py --cfg sft_gsm8k.yaml, you can run python federatedscope/llm/eval/eval_for_gsm8k/eval.py --cfg sft_gsm8k.yaml in the eval_for_gsm8k directory. For other usages, please refer to the README.md file in each subdirectory.
Algorithms
Parameter-Efficient Fine-Tuning
With the help of parameter-efficient fine-tuning methods, federated fine-tuning a large model requires passing only a very small percentage of model parameters (adapters), making it possible for the client to enable efficient adaptation of pre-trained language models to various downstream applications. We adopt PEFT for fine-tuning LLMs, and more methods are coming soon!
| Methods | Source | Example for llm.adapter.args |
|---|---|---|
| LoRA | Link | [ { 'adapter_package': 'peft', 'adapter_method': 'lora', 'r': 8, 'lora_alpha': 32, 'lora_dropout': 0.1 } ] |
| Prefix Tuning | Link, Link | [{'adapter_package': 'peft', 'adapter_method': 'prefix', 'prefix_projection': False, 'num_virtual_tokens': 20}] |
| P-Tuning | Link | [{'adapter_package': 'peft', 'adapter_method': 'p-tuning', 'encoder_reparameterization_type': 'MLP', 'encoder_dropout': 0.1, 'num_virtual_tokens': 20}] |
| Prompt Tuning | Link | [{'adapter_package': 'peft', 'adapter_method': 'prompt', 'prompt_tuning_init': 'RANDOM', 'num_virtual_tokens': 20}] |
Federate fine-tune closed-source LLMs
We support federated fine-tuning not only for open-source LLMs, but also for closed-source LLMs. In this scenario, clients can fine-tune LLMs without fully accessing the model, where models and data are both considered as privacy.
| Methods | Source | How to enable | Note |
|---|---|---|---|
| Offsite-Tuning | Link | llm.offsite_tuning.use=True |
- |
For example, the following methods are supported:
| Methods | Source | How to use | Note |
|---|---|---|---|
| Drop layers | Link | llm.offsite_tuning.emu_l=2llm.offsite_tuning.emu_r=30llm.offsite_tuning.kwargs={"drop_ratio":0.2}} |
The server fixes the first two layers and the layers after 30th layer as the adapter, and uniformly drops 20% of the remaining layers, denoted as the emulator |
| Model distill | Link | llm.offsite_tuning.emu_align.use=Truellm.offsite_tuning.emu_l=2llm.offsite_tuning.emu_r=30 |
The server fixes the first two layers and the layers after 30th layer as the adapter, and regards the remaining as the teacher model, and distills a student model as the emulator |
More methods will be supported ASAP.
Evaluation of fine-tuned closed-source LLMs
To evaluate fine-tuned closed-source LLMs, one should decide whether to evaluate the original model with fine-tuned adapters or the emulator with fine-tuned adapters.
| Methods | Source | How to use | note |
|---|---|---|---|
| Evaluation of fine-tuned closed-source LLMs | Link | cfg.llm.offsite_tuning.eval_type='full' (or 'emu') |
‘full’ means evaluating the original model with fine-tuned adapters; ‘emu’ means evaluating the emulator with fine-tuned adapters |
Federate Fine-tune with Efficiency
To make the federated fine-tuning efficient, we adopt a series of acceleration operators.
| Methods | Source | How to use | Note |
|---|---|---|---|
| torch.nn.DataParallel | Link | cfg.train.data_para_dids=[0,1] |
It splits the input across the specified devices by chunking in the batch dimension. |
| DeepSpeed | Link | cfg.llm.accelation.use=True |
Use nvcc - V to make sure CUDA installed. When set it to True, we can full-parameter fine-tune a llama-7b on a machine with 4 V100-32G gpus. |
| FP16 | Link | train.is_enable_half=True |
Converting float types to half-precision to save memory usage |
| Share local model | - | federate.share_local_model=True |
The clients will share the base model, which reduces a lot of cpu memory consumption. |
| Move to cpu | - | llm.adapter.mv_to_cpu=True |
Move adapter to cpu after training, which can save memory but cost more time. |
FAQ
WARNING: Skip the batch due to the loss is NaN, it may be caused by exceeding the precision or invalid labels.- Possible reason 1: This is because
llm.tok_lenlimits the input length, causing the label to be empty, which automatically skips that data. Setting a largerllm.tok_lencan avoid this. - Possible reason 2: Due to the enabling of
train.is_enable_half, numerical overflow may occur. This usually happens when setting theoptimizer.typetoAdam, since the defaultepsis1e-8butfp16requires at least1e-5.
- Possible reason 1: This is because
ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.- This is a problem with
transformers, you can fix it in your local file. ReplaceLLaMATokenizerwithLlamaTokenizerinPATH_TO_DATA_ROOT/MODEL_REPO/snapshots/..../tokenizer_config.json
- This is a problem with
OutOfMemoryError: CUDA out of memory.- Torch’s garbage collection mechanism may not be timely resulting in OOM, please set
cfg.eval.count_flopstoFalse.
- Torch’s garbage collection mechanism may not be timely resulting in OOM, please set
Citation
If you find FederatedScope-LLM useful for your research or development, please cite the following paper:
@article{kuang2023federatedscopellm,
title={FederatedScope-LLM: A Comprehensive Package for Fine-tuning Large Language Models in Federated Learning},
author={Weirui Kuang and Bingchen Qian and Zitao Li and Daoyuan Chen and Dawei Gao and Xuchen Pan and Yuexiang Xie and Yaliang Li and Bolin Ding and Jingren Zhou},
journal={arXiv preprint arXiv:2309.00363},
year={2023}
}